Python Pandas - Handle Error Data in Dataframe
In many cases, the data that we receive from various sources may not be perfect. That means there may be some missing data. For example, 'empdata1.csv' file contains the following data where employee name is missing in one row and salary and date of joining are missing in another row.
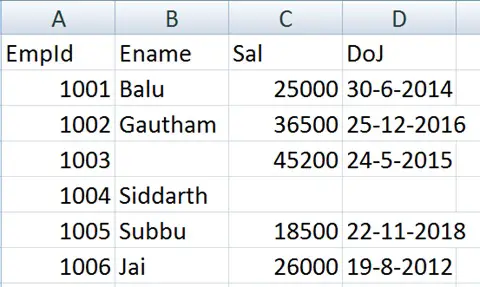
When we convert the data into a data frame, the missing data is represented by NaN (Not a Number). NaN is a default marker for the missing value. Please observe the following data frame:
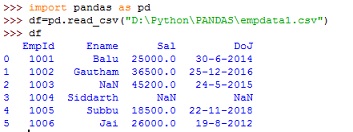
We can use fillna() method to replace the Na or NaN values by a specified value. For example, to fill the NaN values by 0, we can use:
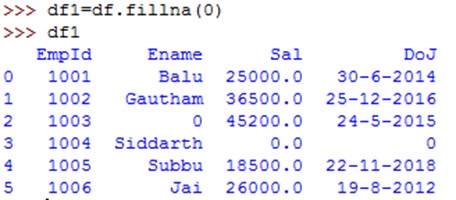
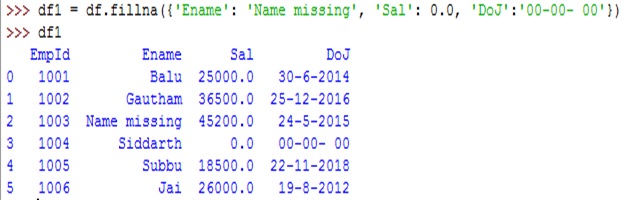
But this is not so useful as it is filling any type of column with zero. We can fill each column with a different value by passing the column names and the value to be used to fill in the column. For example, to fill 'ename' column with 'Name missing', 'sal' with 0.0 and 'doj' with '00-00-00', we should supply these values as a dictionary to fillna() method as shown below:
df1 = df.fillna({'Ename': 'Name missing', 'Sal': 0.0, 'DoJ':'00-00- 00'})
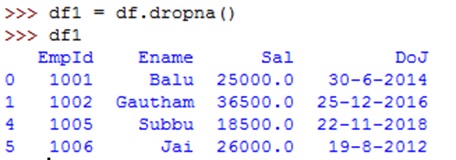
If we do not want the missing data and want to remove those rows having Na or NaN values, then we can use dropna() method as:
df1 = df.dropna()
In this way, filling the necessary data or eliminating the missing data is called 'data cleansing '.