Python Pandas - Dataframe
Data frame is an object that is useful in representing data in the form of rows and columns.For example, the data may come from a file or an Excel spreadsheet or from a Python sequence like a list or tuple. We can represent that data in the form of a data frame. Once the data is stored into the data frame, we can perform various operations that are useful in analyzing and understanding the data.
Data frames are generally created from .csv (comma separated values) files, Excel spreadsheet files, Python dictionaries, list of tuples or list of dictionaries.
Python contains pandas which is a package useful for data analysis and manipulation. Also, xlrd is a package that is useful to retrieve data from Excel files. We should download these packages separately as they are developed by third-party people. DataFrame is the main object in pandas package. We will first discuss various ways of creating data frame objects.
Dataframe from an Excel Spreadsheet
Let us assume that we have a large volume of data present in an Excel spreadsheet file by the name 'empdata.xlsx',
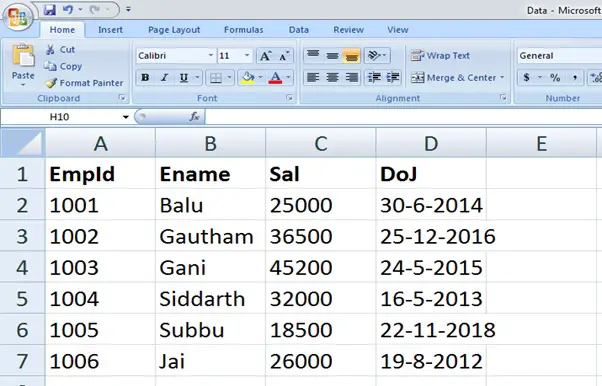
To create the data frames, we should first import the pandas package. We may need xlrd package also that is useful in extracting data from Excel files. To read the data from Excel file, we should use read_excel() function of pandas package in the following format:
read_excel('file path, 'sheet number')
Open the Python IDLE window and type the commands as shown below:
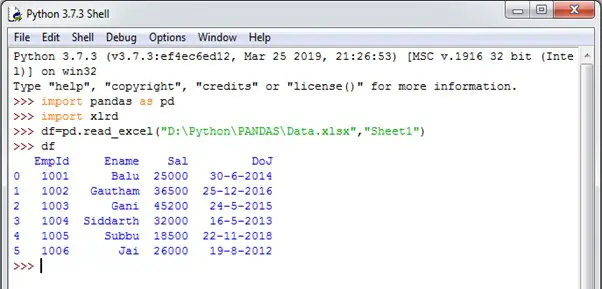

import pandas as pd
import xlrd
df=pd.read_excel('file path, 'sheet number')
Thus, we created the data frame by the name 'df'.Please observe the first column having numbers from 0 to 5.This additional column is called 'index column' and added by the data frame.
Dataframe from .csv file
In many cases, the data will be in the form of .csv files. A .csv file is a comma-separated values file that is similar to an Excel file but it takes less memory. We can create the .csv file by saving the Excel file using the option: File -> Save As and typing the following:
File name: empdata
Save as type: CSV (Comma delimited)
We can read data from a .csv file using read_csv() function that takes the file path as shown below:
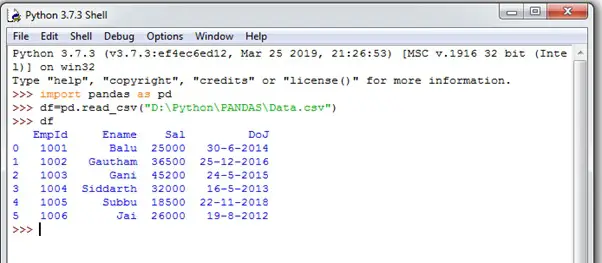
import pandas as pd
import xlrd
df=pd.read_csv()('file path)
Dataframe from Dictionary
It is possible to create a Python dictionary that contains employee data. Let us remember that a dictionary stores data in the form of key-value pairs.In this case, we take 'EmpId', 'Ename', 'Sal', 'DoJ' as keys and corresponding lists as values.Let us first create a dictionary by the name 'empdata' as shown below:
empdata={"EmpId":[1001,1002,1003,1004,1005,1006],"Ename":["Balu","Gautham","Gani","Siddarth","Subbu","Jai"],"Sal":[25000,36500,45200,32000,18500,26000],"DoJ":["30-6-2014","25-12-2016","24-5-2015","16-5-2013","22-11-2018","19-8-2012"]}
>>>df=pd.DataFrame(empdata)
>>df
EmpId Ename Sal DoJ
0 1001 Balu 25000 30-6-2014
1 1002 Gautham 36500 25-12-2016
2 1003 Gani 45200 24-5-2015
3 1004 Siddarth 32000 16-5-2013
4 1005 Subbu 18500 22-11-2018
5 1006 Jai 26000 19-8-2012
Dataframe from List of Tuples
It is possible to create a list of tuples that contains employee data.A tuple can be treated as a row of data.Suppose, if we want to store the data of 6 employees, we have to create 6 tuples.Let us first create a list of 6 tuples by the name 'empdata' as shown below:
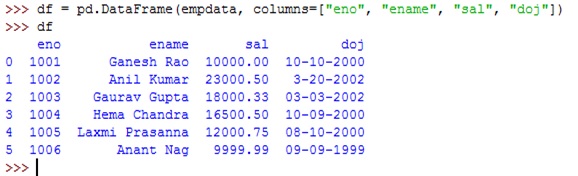
empdata = [(1001, 'Ganesh Rao', 10000.00, '10-10-2000'), (1002, 'Anil Kumar', 23000.50, '3-20-2002'), (1003, 'Gaurav Gupta', 18000.33, '03-03-2002'), (1004, 'Hema Chandra', 16500.50, '10-09-2000'), (1005, 'Laxmi Prasanna', 12000.75, '08-10-2000'), (1006, 'Anant Nag', 9999.99, '09-09-1999')]Now, let us convert this list of tuples into a data frame by passing this dictionary to DataFrame class object as:
df = pd.DataFrame(empdata, columns=["eno", "ename", "sal", "doj"])
Since the original list of tuples does not have column names, we have to include the column names while creating the data frame as shown in the preceding statement.